深度学习中各种卷积总结
在深度学习中,卷积是一个非常重要的概念,卷积也是卷积神经网络拥有良好的图像处理能力的关键。 这篇文章将介绍一下不同类型的卷积,为了简单起见,本文只关注于二维的卷积。
参考论文:A guide to convolution arithmetic for deep learning
卷积动画:https://github.com/vdumoulin/conv_arithmetic
普通卷积(Convolution)
首先我们先回忆一下卷积的基本概念:
卷积核大小(Kernel Size):卷积核的大小定义了卷积操作的感受野。在二维卷积中,通常设置为3,即卷积核大小为3×3。
步长(Stride):定义了卷积核遍历图像时的步幅大小。其默认值通常设置为1,也可将步幅设置为2后对图像进行下采样,这种方式与最大池化类似。
填充(Padding):定义了网络层处理样本边界的方式。当卷积核大于1且不进行边界扩充,输出尺寸将相应缩小;当卷积核以标准方式进行边界扩充,则输出数据的空间尺寸将与输入相等。
输入和输出通道(Channel):构建卷积层时需定义输入通道$I$,并由此确定输出通道$O$。这样,可算出每个网络层的参数量为$I*O*K$,其中$K$为卷积核的参数个数。例如,某个网络层有64个大小为3×3的卷积核,则对应$K$值为 3×3 =9。
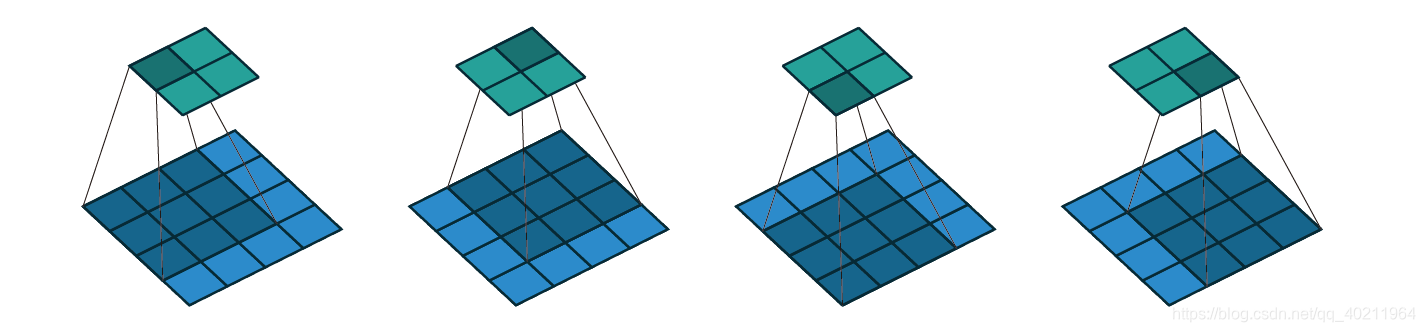
如图所示卷积是一个相当简单的操作:从卷积核开始,这是一个小的权值矩阵。这个卷积核在 输入数据上“滑动”,对当前输入的部分元素进行矩阵乘法,然后将结果汇为feature map。
$\bigtriangledown$ 卷积核大小为3、步长为2、填充为0的二维卷积(蓝色为输入,绿色为输出)

$\bigtriangledown$ 卷积核大小为3、步长为1、填充为1的二维卷积
转置卷积/反卷积(Transposed convolution)
我们一般可以通过卷积操作来实现高维特征到低维特征的转换,而如果想要将这一过程反过来,即由低维特征恢复到高维特征,我们可以借由转置卷积来实现。
之所以叫转置卷积是因为,它其实是把我们平时所用正常卷积操作中的卷积核做一个转置,然后把正常卷积的输出作为转置卷积的输入,而转置卷积的输出,就是正常卷积的输入。
那么具体怎么实现的呢,让我们先来将正常卷积换一个写法:
这是一个4x4的输入,经过一个3x3的卷积核(步长为1,填充为0),得到的是2x2的输出。
本来输入输出都是矩阵的形式,现在我们把他们变成向量的形式,也就是把输入reshape成16x1,把输出reshape成4x1。那么相应的,想要由16x1的输入得到4x1的输出,卷积核就得变成4x16的。我们就可以把卷积核写成这个亚子:

用$x,C,z$分别表示变换之后的输入、卷积核和输出,那么正常卷积就可以这样写:$z = Cx$
这个就是正常卷积的过程:由输入和卷积核得到输出。
那么反过来由输出和卷积核的转置就能得到输入:$x = C^Tz$
这就是转置卷积的由来。
让我们来看几个例子:
-
首先是正常卷积步长s=1的时候,其对应的转置矩阵卷积核大小不变的情况下,我们可以通过填充来实现转置卷积。
$\bigtriangledown$ 卷积核大小为3×3、步长为1和无填充的正常卷积;输入为4x4,输出为2x2

$\bigtriangledown$ 卷积核大小为3×3、步长为1和填充为2的转置卷积;输入为2x2,输出为4x4

-
如果正常卷积步长为s>1时,希望其对应的转置卷积步长为$\frac{1}{s}$,我们需要在输入中插入s-1个0来实现转置矩阵的步长s<1的效果。步长s<1的转置卷积也称为微步卷积(Fractionally-strided convolution)。
$\bigtriangledown$ 卷积核大小为3×3、步长为2和无填充的正常卷积;输入为5x5,输出为2x2
$\bigtriangledown$ 卷积核大小为3×3、步长为1/2和填充为2的转置卷积;输入为2x2,输出为5x5

注意的是:其实严格意义上转置卷积不是反卷积。
反卷积在数学含义上是可以完全还原输入信号的是卷积的逆过程;但是转置卷积只能还原到原来输入的shape,重建先前的空间分辨率,执行了卷积操作,其value值是不一样的,并不是卷积的数学逆过程。
但是应用于编码器-解码器结构中,转置矩阵仍然很有用。这样转置卷积就可以同时实现图像的粗粒化(upscaling)和卷积操作,而不是通过两个单独过程来完成了。并且转置卷积常常用于CNN中对特征图进行上采样,比如语义分割和超分辨率任务中。
空洞卷积/膨胀卷积(Dilated convolution)
参考论文:Multi-Scale Context Aggregation by Dilated Convolutions
空洞卷积(又名膨胀卷积),是一种不增加参数数量,但却增加感受野的特殊卷积。它通过给卷积核插入“空洞”来变相地增加其大小,只是引入了一个称为 “膨胀率(dilation rate)”的超参数。
如果膨胀率为d,那么就会在卷积核的每两个元素之间插入d-1个空洞。当d=1时卷积核为普通的卷积核。
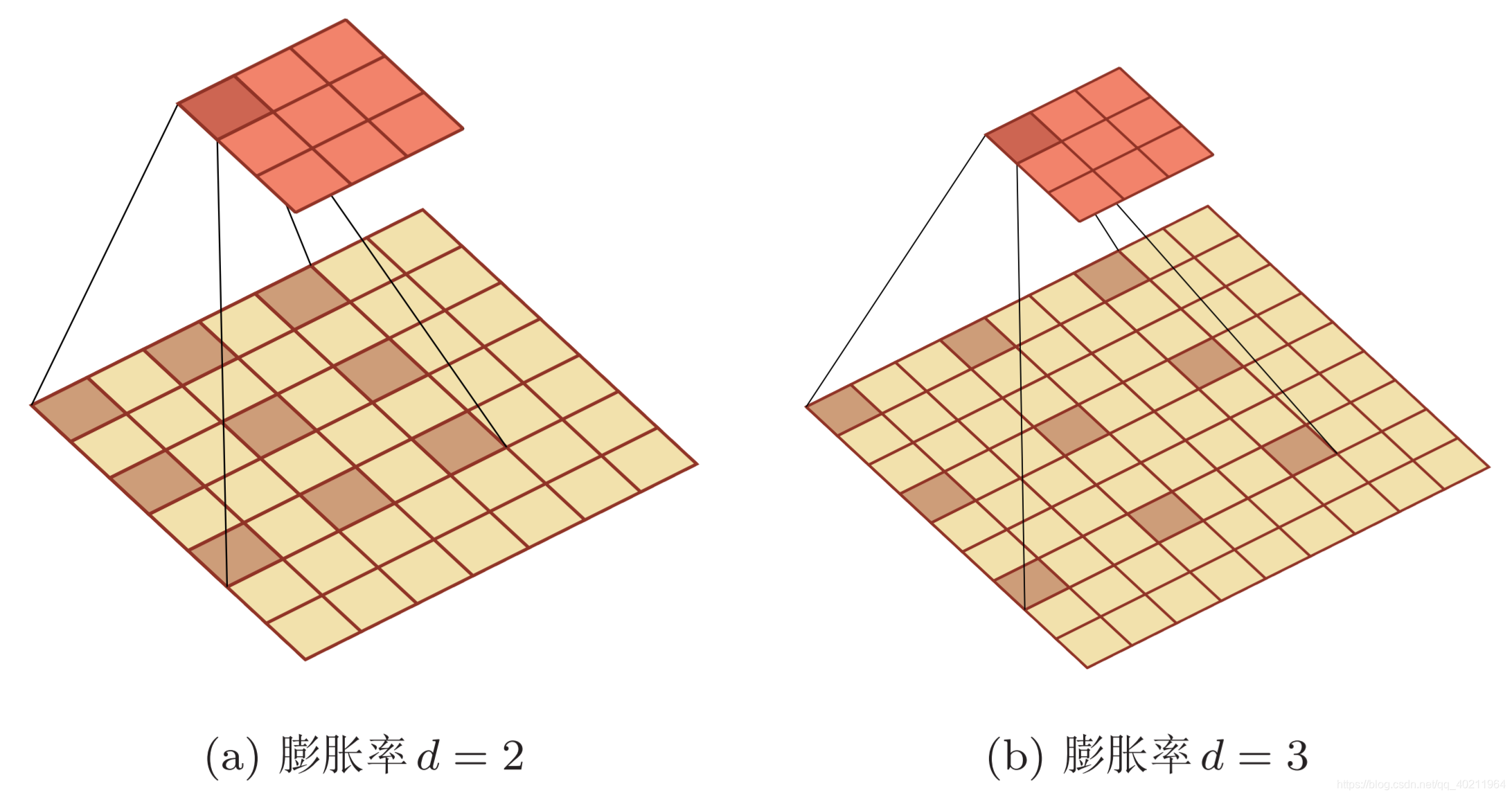
$\bigtriangledown$ 卷积核大小为3、步长为1、填充为0、膨胀率为2的二维卷积
在相同的计算条件下,空洞卷积提供了更大的感受野。空洞卷积经常用在实时图像分割中。当网络层需要较大的感受野,但计算资源有限而无法提高卷积核数量或大小时,可以考虑空洞卷积。